 اگر بتوان یادداشتها را به موجود زنده تبدیل کرد که خودشان حرف بزنند میتوان مشکلات را کاهش داد. گویی خود آن موجود دستش را بالا میگیرد و اعلام میکند با داده جدید تعارض دارد و لذا یا نباید وارد موجودیت وی شود، و یا در غیر این صورت باید برخی دادهها حذف شوند.
اگر بتوان یادداشتها را به موجود زنده تبدیل کرد که خودشان حرف بزنند میتوان مشکلات را کاهش داد. گویی خود آن موجود دستش را بالا میگیرد و اعلام میکند با داده جدید تعارض دارد و لذا یا نباید وارد موجودیت وی شود، و یا در غیر این صورت باید برخی دادهها حذف شوند.
به گزارش خبرنگار پایگاه خبری تحلیلی مفتاح علوم انسانی اسلامی، به گزارش روابط عمومی پژوهشگاه فرهنگ و اندیشه اسلامی، بخش اول نشست “سیاستگذاری و هوش مصنوعی توضیحپذیر: ماجرای داده” با ارائه حجتالاسلام علیرضا شهبازی (دانش آموخته لیسانس برق شریف، طلبه سطح چهار حوزه و بنیانگذار شرکت برهان) روز یکشنبه ۳۰ اردیبهشت به صورت آنلاین به میزبانی هستۀ حکمرانی و هوش مصنوعی مرکز رشد و نوآوری پژوهشگاه برگزار شد.
شهبازی ابتدا به انواع نحوههای کتابت از حیث فرم و محتوا پرداخت که میتواند کتاب و مقاله و پست، یا دایره المعارف، کتاب لغت و اصطلاحنامه باشد. سپس با افزایش تعدد و تنوع کتابها در عصر قدیم، فهرستنگاری مکتوبات برای معرفی عنوان و توضیح مختصر درباره آنها تهیه و شیوهای رایج شد. طبقهبندی و ردهبندی، و درختوارۀ موضوعی شیوههای دیگری از مکتوب کردن دانش درکنار فهرستنویسی بوده است.
وی به کارکردهای کتابت پرداخت که شامل از بین نرفتن دادهها، تحلیل و بررسی، انتشار، بازیابی و تفاهم است. چالشهای استفادۀ ما از نحوههای کتابت در عصر ما گستردگی اطلاعات، دقیق نبودن داده و تفاسیر متعدد است. حجم گستردۀ منابع و اطلاعات چالشهایی از قبیل توجه به مسائل جدید، مکتوبات جدید و التفات همهجانبه را ایجاد میکند.
در این راستا نیاز به تجمیع قرائن بسیار زیاد احساس میشود، اما تجمیع قرائن هم دو چالش دارد؛ اولاً منطقهای متفاوتی در تجمیع قرائن وجود دارد، و ثانیاً دسترسی ما به قرائن جدید محدودیت دارد. این موضوع به صورت بزرگتر در روند تغییر دانش در طول زمان به وجود میآید؛ یعنی دانش در طول زمان فرسایش مییابد، نتایج وابسته به مکتوب ممکن است حذف شود، و لوازم یک نظریه فراموش میشود. سازگاری و انسجام یک نظریه در مقام قواعد و در مقام تطبیق نیز چالش در تغییر دانش ایجاد میکند.
برای رفع این چالش با جستوجوی دقیق با دشواری جستوجوی فرالفظی و نگاه تمامجانبه به تتبعات مواجهیم. برای تولید محتوای جدید با مشکلاتی از قبیل بیان دانش در زبانهای دیگر، طرح مسائل جدید و تحقیقات آماری نیز روبهروییم.
شهبازی ادامه داد: یکی از چالشهای کتابت گفتیم که تکرار محتواست و برای جلوگیری از آن لازم است نگاه به دانش تغییر کند و به جای نگهداری طولی، شبکه دایروی طراحی کنیم که نسبتها را به صورت علت و معلول، مؤید، متناقض، و… مطرح میکند. در این صورت، به جای اینکه چندین بار مکتوبات بازیابی شوند، یک بار بازیابی میشوند.
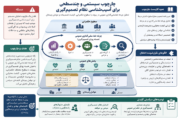
وی راهحلهای ممکن برای رفع چالشها را حرکت به سمت ساختاریافته کردن مکتوبات دانست که امروز به هستیشناسی داده رسیده است. در این زمینه لازم است انواع کتابت تدقیق شوند؛ “داده: مقادیر عددی یا رشتهای”، “اطلاعات: معنابخشی و ساختاردهی به دادگان”، و “دانش: هرآنچه در مورد چیزی میدانیم” است.
شهبازی به روشهای ساختاریافته کردن دادهها اشاره کرد و گفت یکی از این روشها دائره المعارف است که باعث بازیابی بهتر اطلاعات میشود. علاوه بر آن، گراف دانش است. از نمونههای گراف دانش DBPedia است که اطلاعات ویکیپدیا را در قالب گراف دانش جمعآوری کرده است. همچنین Google Knowledge Graph است که به نتایج جستوجوی گوگل ساختار داده و خود گوگل پاسخ متداول را به جستوجوی سؤالی ارائه میکند. قمنت هم از پروژههای ارائهدهنده در این زمینه است.
به علاوه، استفاده از هستیشناسی داده و هستاننگاری برای معنابخشی به گراف روش رایجی است. پایگاه DBPedia اطلاعات را وجودیابی میکند که هر چیزی، چه نوع و ماهیتی دارد. گوگل هم از گراف دانش استفاده میکند. قمنت (qomnet.ir) گراف برخاسته از ویکیهای اسلامی است.
وی ارتباط چالشهای کتابت و انتقال داده را با مباحث هوش مصنوعی بیان کرد: اگر بتوان یادداشتها را به موجود زنده تبدیل کرد که خودشان حرف بزنند میتوان مشکلات را کاهش داد. گویی خود آن موجود دستش را بالا میگیرد و اعلام میکند با داده جدید تعارض دارد و لذا یا نباید وارد موجودیت وی شود، و یا در غیر این صورت باید برخی دادهها حذف شوند. ما از اینجا میتوانیم به نشست بعدی برویم: اتفاقات مختلفی در اینجا میافتد که هرکدام مزایا و معایبی دارند.
آخر نشست به پرسش و پاسخ اختصاص یافت و درباره نسبت LLM با هستیشناسی و… مطالبی مطرح شد. بخش دوم این نشست به زودی اطلاعرسانی خواهد شد.
https://ihkn.ir/?p=37691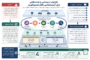




















نظرات